回测
回测用给定模型获得的历史上的模拟预测,是用来评测模型预测准曲率的重要工具。

回测是一个迭代过程,回测用固定预测窗口在数据集上进行重复预测,然后通过固定步长向前移动到训练集的末尾。如上图所示,桔色部分是长度为3的预测窗口。在每次迭代中,预测窗口会向前移动3个长度,同样训练集也会向后扩张三个长度。这个过程会持续到窗口移动到数据末尾。
示例
1)数据准备
from paddlets.datasets.repository import get_dataset
dataset = get_dataset('WTH')
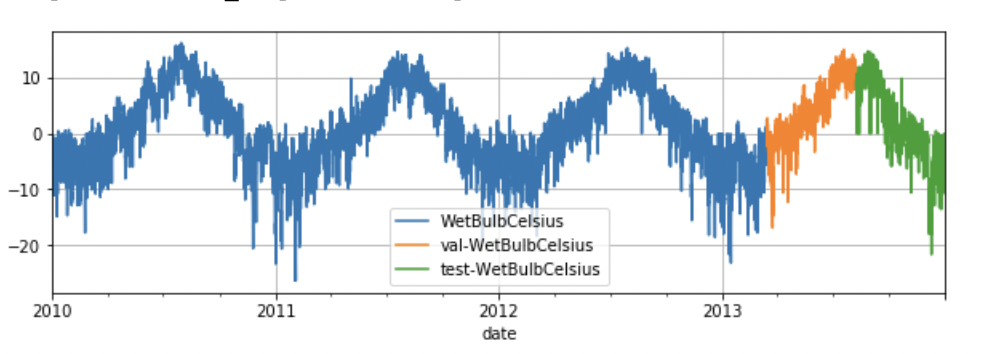
train_dataset, val_test_dataset = dataset.split(0.8)
val_dataset, test_dataset = val_test_dataset.split(0.5)
train_dataset.plot(add_data=[val_dataset,test_dataset],labels=["val","test"])
2)模型拟合
from paddlets.models.dl.paddlepaddle import MLPRegressor
mlp = MLPRegressor(
in_chunk_len = 7 * 96,
out_chunk_len = 96,
max_epochs=100
)
mlp.fit(train_dataset, val_dataset)
3)回测
下面举了5个关于回测的例子,如果需要更多关于回测的信息请阅读 Backtesting API doc 。
回测示例1
默认情况下回测在模型input_chunk_length的位置开始并返回一个MSE评估指标。
from paddlets.utils import backtest
score= backtest(
data=test_dataset,
model=mlp
)
print(score)
#1.7069822928807792
回测示例2
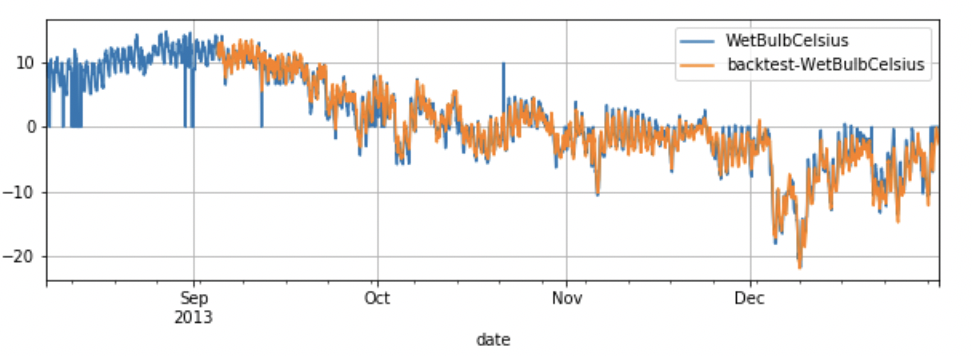
如果设置 return_score 为 False,回测函数会返回 TSDataset 。
from paddlets.utils import backtest
preds_data= backtest(
data=test_dataset,
model=mlp,
return_score =False)
val_test_dataset.plot(add_data=preds_data,labels="backtest")
回测示例3
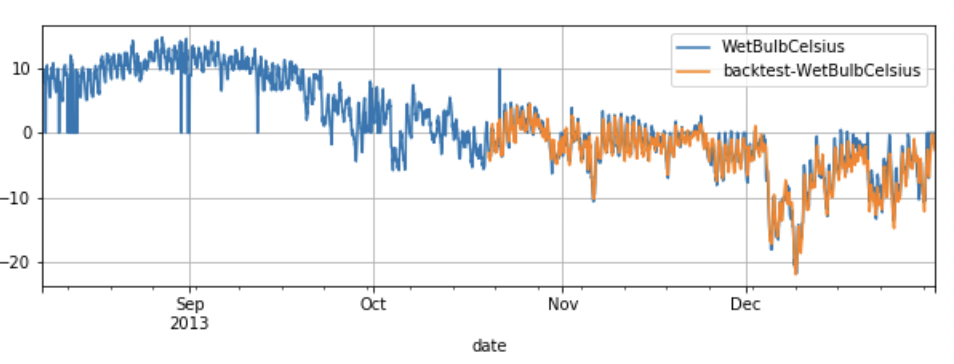
start 可以控制回测的起始点如果设置 start 为0.5,那么回测将会在数据的中间位置开始。
from paddlets.utils import backtest
preds_data= backtest(
data=test_dataset,
model=mlp,
start =0.5,
return_score =False)
test_dataset.plot(add_data=preds_data,labels="backtest")
回测示例4
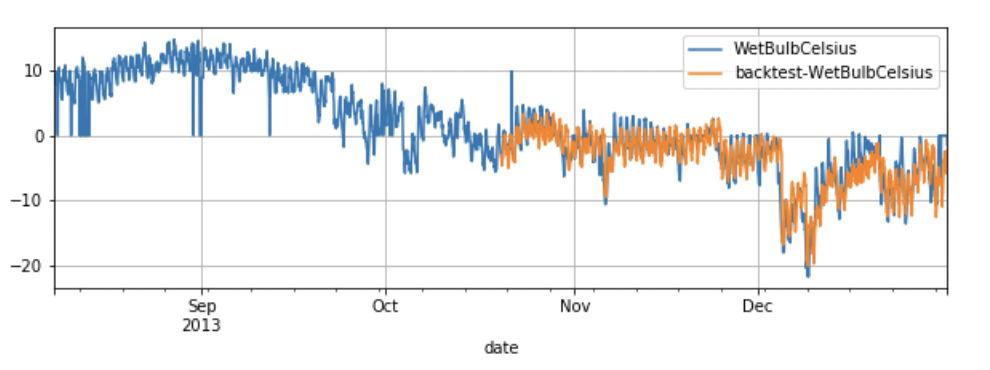
predict_window 是每次预测的窗口长度。stride 是两次连续预测之间的移动步长。在大多数情况下我们需要自定义这两个参数来模拟真是的预测场景。
from paddlets.utils import backtest
preds_data= backtest(
data=test_dataset,
model=mlp,
start =0.5,
predict_window=24,
stride=24,
return_score =False)
test_dataset.plot(add_data=preds_data,labels="backtest")
回测示例5
如果设置 predict_window != stride 并且 predict_window != stride ,回测函数会返回一个TSdataset 的list。 因为预测结果相互重叠或相互间隔无法组成完整TSDataset。
from paddlets.utils import backtest
preds_data= backtest(
data=test_dataset,
model=mlp,
predict_window=24,
stride=12,
return_score =False)
type(preds_data)
#list[TSdataset]